![]()
[Mar 24, 2025] Get New DEA-C01 Certification Practice Test Questions Exam Dumps
Real DEA-C01 Exam Dumps Questions Valid DEA-C01 Dumps PDF
NEW QUESTION # 56
A manufacturing company collects sensor data from its factory floor to monitor and enhance operational efficiency. The company uses Amazon Kinesis Data Streams to publish the data that the sensors collect to a data stream. Then Amazon Kinesis Data Firehose writes the data to an Amazon S3 bucket.
The company needs to display a real-time view of operational efficiency on a large screen in the manufacturing facility.
Which solution will meet these requirements with the LOWEST latency?
- A. Use AWS Glue bookmarks to read sensor data from the S3 bucket in real time. Publish the data to an Amazon Timestream database. Use the Timestream database as a source to create a Grafana dashboard.
- B. Use Amazon Managed Service for Apache Flink (previously known as Amazon Kinesis Data Analytics) to process the sensor data. Use a connector for Apache Flink to write data to an Amazon Timestream database. Use the Timestream database as a source to create a Grafana dashboard.
- C. Configure the S3 bucket to send a notification to an AWS Lambda function when any new object is created. Use the Lambda function to publish the data to Amazon Aurora. Use Aurora as a source to create an Amazon QuickSight dashboard.
- D. Use Amazon Managed Service for Apache Flink (previously known as Amazon Kinesis Data Analytics) to process the sensor data. Create a new Data Firehose delivery stream to publish data directly to an Amazon Timestream database. Use the Timestream database as a source to create an Amazon QuickSight dashboard.
Answer: B
Explanation:
Amazon Managed Service for Apache Flink provides real-time stream processing capabilities, which can process sensor data with low latency. By using Apache Flink connectors, the processed data can be efficiently written to Amazon Timestream, which is optimized for time- series data storage and querying.
NEW QUESTION # 57
A data engineer needs to debug an AWS Glue job that reads from Amazon S3 and writes to Amazon Redshift. The data engineer enabled the bookmark feature for the AWS Glue job.
The data engineer has set the maximum concurrency for the AWS Glue job to 1.
The AWS Glue job is successfully writing the output to Amazon Redshift. However, the Amazon S3 files that were loaded during previous runs of the AWS Glue job are being reprocessed by subsequent runs.
What is the likely reason the AWS Glue job is reprocessing the files?
- A. The maximum concurrency for the AWS Glue job is set to 1.
- B. The AWS Glue job does not have a required commit statement.
- C. The data engineer incorrectly specified an older version of AWS Glue for the Glue job.
- D. The AWS Glue job does not have the s3:GetObjectAcl permission that is required for bookmarks to work correctly.
Answer: B
Explanation:
https://docs.aws.amazon.com/glue/latest/dg/glue-troubleshooting-errors.html#error-job- bookmarks-reprocess-data
NEW QUESTION # 58
Jeff, a Data Engineer, accessing elements in JSON object in its 3 data loading scripts, he unknow-ingly use the upper case while accessing the elements. e.g.
Script 1 --> fruits:apple.sweet
Script 2 --> FRUITS:apple.sweet
Script 3 --> FRUITS:Apple.Sweet
Which are the correct statements?
- A. Script 2&3 traverse path will be same.
- B. Script 1 & 3 traverse path will be treated in same way.
- C. Script 1 & Script 2 traverse path twill be treated same, but Script 2 will not.
- D. Script 1,2,3 traverse path will treat in same way.
Answer: C
Explanation:
Explanation
There are two ways to access elements in a JSON object:
Dot Notation
Bracket Notation
Regardless of which notation you use, the column name is case-insensitive but element names are case-sensitive.
NEW QUESTION # 59
A company needs to build a data lake in AWS. The company must provide row-level data access and column-level data access to specific teams. The teams will access the data by using Amazon Athena, Amazon Redshift Spectrum, and Apache Hive from Amazon EMR.
Which solution will meet these requirements with the LEAST operational overhead?
- A. Use Amazon S3 for data lake storage. Use Apache Ranger through Amazon EMR to restrict data access by rows and columns. Provide data access by using Apache Pig.
- B. Use Amazon Redshift for data lake storage. Use Redshift security policies to restrict data access by rows and columns. Provide data access by using Apache Spark and Amazon Athena federated queries.
- C. Use Amazon S3 for data lake storage. Use S3 access policies to restrict data access by rows and columns. Provide data access through Amazon S3.
- D. Use Amazon S3 for data lake storage. Use AWS Lake Formation to restrict data access by rows and columns. Provide data access through AWS Lake Formation.
Answer: D
Explanation:
https://docs.aws.amazon.com/lake-formation/latest/dg/cbac-tutorial.html
NEW QUESTION # 60
Data Engineer Loading File named snowdata.tsv in the /datadir directory from his local machine to Snowflake stage and try to prefix the file with a folder named tablestage, please mark the correct command which helps him to load the files data into snowflake internal Table stage?
- A. put file://c:\datadir\snowdata.tsv @tablestage;
- B. put file://c:\datadir\snowdata.tsv @%tablestage;
- C. put file:///datadir/snowdata.tsv @%tablestage;
- D. put file://c:\datadir\snowdata.tsv @~/tablestage;
Answer: B
Explanation:
Explanation
Execute PUT to upload (stage) local data files into an internal stage.
@% character combination identifies a table stage.
NEW QUESTION # 61
The Snowpipe API provides REST endpoints for fetching load reports. One of the Endpoint named insertReport helps to retrieves a report of files submitted via insertFiles end point whose contents were recently ingested into a table. A success response (200) contains information about files that have recently been added to the table. Response Looks like below:
1.{
2."pipe": "SNOWTESTDB.SFTESTSCHEMA.SFpipe",
3."completeResult": true,
4."nextBeginMark": "1_16",
5."files": [
6.{
7."path": "data4859992083898.csv",
8."stageLocation": "s3://mybucket/",
9."fileSize": 89,
10."timeReceived": "2022-01-31T04:47:41.453Z",
11."lastInsertTime": "2022-01-31T04:48:28.575Z",
12."rowsInserted": 1,
13."rowsParsed": 1,
14."errorsSeen": 0,
15."errorLimit": 1,
16."complete": true,
17."status": "????"
18.}
19.]
20.}
Which one is the correct value of status string data in the Response Body?
- A. LOAD_SUCCESS
- B. LOADED
- C. SUCCESS
- D. LOADED_SUCCESS
Answer: A
Explanation:
Explanation
Permissible Load status for the file:
LOAD_IN_PROGRESS: Part of the file has been loaded into the table, but the load process has not completed yet.
LOADED: The entire file has been loaded successfully into the table.
LOAD_FAILED: The file load failed.
PARTIALLY_LOADED: Some rows from this file were loaded successfully, but others were not loaded due to errors. Processing of this file is completed.
Please not the different Response Codes available with their meaning.
200 - Success. Report returned.
400 - Failure. Invalid request due to an invalid format, or limit exceeded.
404 - Failure. pipeName not recognized.
This error code can also be returned if the role used when calling the endpoint does not have suffi-cient privileges. For more information, see Granting Access Privileges.
429 - Failure. Request rate limit exceeded.
500 - Failure. Internal error occurred.
As you could understand from the questions, there is 200 Success response returned, Status in the response body would be LOADED.
NEW QUESTION # 62
A company wants to use machine learning (ML) to perform analytics on data that is in an Amazon S3 data lake. The company has two data transformation requirements that will give consumers within the company the ability to create reports.
The company must perform daily transformations on 300 GB of data that is in a variety format that must arrive in Amazon S3 at a scheduled time. The company must perform one-time transformations of terabytes of archived data that is in the S3 data lake. The company uses Amazon Managed Workflows for Apache Airflow (Amazon MWAA) Directed Acyclic Graphs (DAGs) to orchestrate processing.
Which combination of tasks should the company schedule in the Amazon MWAA DAGs to meet these requirements MOST cost-effectively? (Choose two.)
- A. For daily incoming data, use AWS Glue crawlers to scan and identify the schema.
- B. For daily incoming data, use Amazon Redshift to perform transformations.
- C. For daily incoming data, use Amazon Athena to scan and identify the schema.
- D. For archived data, use Amazon SageMaker to perform data transformations.
- E. For daily and archived data, use Amazon EMR to perform data transformations.
Answer: A,E
NEW QUESTION # 63
Which one is not the Core benefits of micro-partitioning
- A. Enables extremely efficient DML and fine-grained pruning for faster queries.
- B. Columns are also compressed individually within micro-partitions.
- C. Micro-partitions can overlap in their range of values, helps data skewing.
- D. Columns are stored independently within micro-partitions, often referred to as colum-nar storage.
- E. Snowflake micro-partitions are derived automatically they do not need to be explicitly defined up-front or maintained by users.
Answer: C
Explanation:
Explanation
The benefits of Snowflake's approach to partitioning table data include:
In contrast to traditional static partitioning, Snowflake micro-partitions are derived automatically; they don't need to be explicitly defined up-front or maintained by users.
As the name suggests, micro-partitions are small in size (50 to 500 MB, before compression), which enables extremely efficient DML and fine-grained pruning for faster queries.
Micro-partitions can overlap in their range of values, which, combined with their uniformly small size, helps prevent skew.
Columns are stored independently within micro-partitions, often referred to as columnar storage. This enables efficient scanning of individual columns; only the columns referenced by a query are scanned.
Columns are also compressed individually within micro-partitions. Snowflake automatically de-termines the most efficient compression algorithm for the columns in each micro-partition.
NEW QUESTION # 64
A company wants to implement real-time analytics capabilities. The company wants to use Amazon Kinesis Data Streams and Amazon Redshift to ingest and process streaming data at the rate of several gigabytes per second. The company wants to derive near real-time insights by using existing business intelligence (BI) and analytics tools.
Which solution will meet these requirements with the LEAST operational overhead?
- A. Access the data from Kinesis Data Streams by using SQL queries. Create materialized views directly on top of the stream. Refresh the materialized views regularly to query the most recent stream data.
- B. Create an external schema in Amazon Redshift to map the data from Kinesis Data Streams to an Amazon Redshift object. Create a materialized view to read data from the stream. Set the materialized view to auto refresh.
- C. Use Kinesis Data Streams to stage data in Amazon S3. Use the COPY command to load data from Amazon S3 directly into Amazon Redshift to make the data immediately available for real- time analysis.
- D. Connect Kinesis Data Streams to Amazon Kinesis Data Firehose. Use Kinesis Data Firehose to stage the data in Amazon S3. Use the COPY command to load the data from Amazon S3 to a table in Amazon Redshift.
Answer: B
Explanation:
https://docs.aws.amazon.com/redshift/latest/dg/materialized-view-streaming-ingestion.html
NEW QUESTION # 65
Which Snowflake feature facilitates access to external API services such as geocoders. data transformation, machine Learning models and other custom code?
- A. Java User-Defined Functions (UDFs)
- B. Security integration
- C. External tables
- D. External functions
Answer: D
Explanation:
Explanation
External functions are Snowflake functions that facilitate access to external API services such as geocoders, data transformation, machine learning models and other custom code. External functions allow users to invoke external services from within SQL queries and pass arguments and receive results as JSON values. External functions require creating an API integration object and an external function object in Snowflake, as well as deploying an external service endpoint that can communicate with Snowflake via HTTPS.
NEW QUESTION # 66
A company uses AWS Step Functions to orchestrate a data pipeline. The pipeline consists of Amazon EMR jobs that ingest data from data sources and store the data in an Amazon S3 bucket. The pipeline also includes EMR jobs that load the data to Amazon Redshift.
The company's cloud infrastructure team manually built a Step Functions state machine. The cloud infrastructure team launched an EMR cluster into a VPC to support the EMR jobs.
However, the deployed Step Functions state machine is not able to run the EMR jobs.
Which combination of steps should the company take to identify the reason the Step Functions state machine is not able to run the EMR jobs? (Choose two.)
- A. Check the retry scenarios that the company configured for the EMR jobs. Increase the number of seconds in the interval between each EMR task. Validate that each fallback state has the appropriate catch for each decision state. Configure an Amazon Simple Notification Service (Amazon SNS) topic to store the error messages.
- B. Query the flow logs for the VPC. Determine whether the traffic that originates from the EMR cluster can successfully reach the data providers. Determine whether any security group that might be attached to the Amazon EMR cluster allows connections to the data source servers on the informed ports.
- C. Use AWS CloudFormation to automate the Step Functions state machine deployment. Create a step to pause the state machine during the EMR jobs that fail. Configure the step to wait for a human user to send approval through an email message. Include details of the EMR task in the email message for further analysis.
- D. Verify that the Step Functions state machine code has all IAM permissions that are necessary to create and run the EMR jobs. Verify that the Step Functions state machine code also includes IAM permissions to access the Amazon S3 buckets that the EMR jobs use. Use Access Analyzer for S3 to check the S3 access properties.
- E. Check for entries in Amazon CloudWatch for the newly created EMR cluster. Change the AWS Step Functions state machine code to use Amazon EMR on EKS. Change the IAM access policies and the security group configuration for the Step Functions state machine code to reflect inclusion of Amazon Elastic Kubernetes Service (Amazon EKS).
Answer: B,D
Explanation:
https://docs.aws.amazon.com/step-functions/latest/dg/procedure-create-iam-role.html
https://docs.aws.amazon.com/step-functions/latest/dg/service-integration-iam-templates.html
NEW QUESTION # 67
SYSTEM$CLUSTERING_INFORMATION functions returns clustering information, including average clustering depth, for a table based on one or more columns in the table. The function returns a JSON object containing average_overlaps name/value pairs. Does High average_overlaps indicates well organized Clustering?
- A. YES
- B. NO
Answer: B
Explanation:
Explanation
Higher the avg_overlap indicates poorly organized clustering.
NEW QUESTION # 68
For SQL UDFs, The invoker of the function need not have access to the objects referenced in the function definition, but only needs the privilege to use the function?
- A. FALSE
- B. TRUE
Answer: B
NEW QUESTION # 69
A data engineer is configuring an AWS Glue job to read data from an Amazon S3 bucket. The data engineer has set up the necessary AWS Glue connection details and an associated IAM role. However, when the data engineer attempts to run the AWS Glue job, the data engineer receives an error message that indicates that there are problems with the Amazon S3 VPC gateway endpoint.
The data engineer must resolve the error and connect the AWS Glue job to the S3 bucket.
Which solution will meet this requirement?
- A. Configure an S3 bucket policy to explicitly grant the AWS Glue job permissions to access the S3 bucket.
- B. Update the AWS Glue security group to allow inbound traffic from the Amazon S3 VPC gateway endpoint.
- C. Verify that the VPC's route table includes inbound and outbound routes for the Amazon S3 VPC gateway endpoint.
- D. Review the AWS Glue job code to ensure that the AWS Glue connection details include a fully qualified domain name.
Answer: C
Explanation:
https://docs.aws.amazon.com/glue/latest/dg/connection-VPC-disable-proxy.html
https://docs.aws.amazon.com/glue/latest/dg/connection-S3-VPC.html
NEW QUESTION # 70
A Data Engineer is trying to load the following rows from a CSV file into a table in Snowflake with the following structure: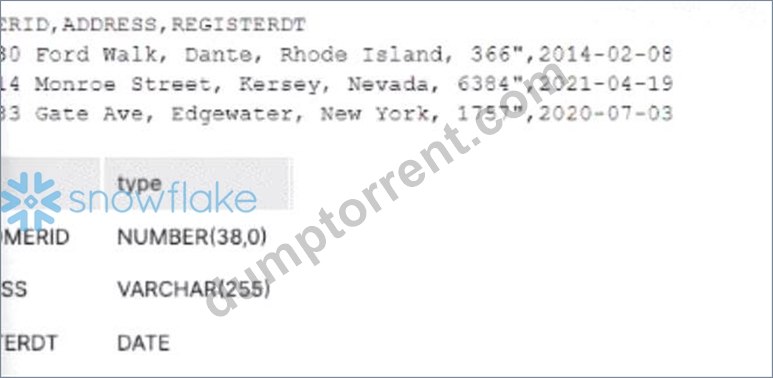
....engineer is using the following COPY INTO statement:
However, the following error is received.
Which file format option should be used to resolve the error and successfully load all the data into the table?
- A. FIELD OPTIONALLY ENCLOSED BY = " "
- B. ERROR_ON_COLUMN_COUKT_MISMATCH = FALSE
- C. FIELD_DELIMITER = ","
- D. ESC&PE_UNENGLO9ED_FIELD = '\\'
Answer: A
Explanation:
Explanation
The file format option that should be used to resolve the error and successfully load all the data into the table is FIELD_OPTIONALLY_ENCLOSED_BY = '"'. This option specifies that fields in the file may be enclosed by double quotes, which allows for fields that contain commas or newlines within them. For example, in row 3 of the file, there is a field that contains a comma within double quotes: "Smith Jr., John". Without specifying this option, Snowflake will treat this field as two separate fields and cause an error due to column count mismatch. By specifying this option, Snowflake will treat this field as one field and load it correctly into the table.
NEW QUESTION # 71
A company stores details about transactions in an Amazon S3 bucket. The company wants to log all writes to the S3 bucket into another S3 bucket that is in the same AWS Region.
Which solution will meet this requirement with the LEAST operational effort?
- A. Create a trail of management events in AWS CloudTraiL. Configure the trail to receive data from the transactions S3 bucket. Specify an empty prefix and write-only events. Specify the logs S3 bucket as the destination bucket.
- B. Configure an S3 Event Notifications rule for all activities on the transactions S3 bucket to invoke an AWS Lambda function. Program the Lambda function to write the event to Amazon Kinesis Data Firehose. Configure Kinesis Data Firehose to write the event to the logs S3 bucket.
- C. Configure an S3 Event Notifications rule for all activities on the transactions S3 bucket to invoke an AWS Lambda function. Program the Lambda function to write the events to the logs S3 bucket.
- D. Create a trail of data events in AWS CloudTraiL. Configure the trail to receive data from the transactions S3 bucket. Specify an empty prefix and write-only events. Specify the logs S3 bucket as the destination bucket.
Answer: D
Explanation:
https://docs.aws.amazon.com/AmazonS3/latest/userguide/logging-with-S3.html
NEW QUESTION # 72
The COPY command supports several options for loading data files from a stage i.e.
I. By path
II. Specifying a list of specific files to load.
III. Using pattern matching to identify specific files by pattern.
IV. Organize files into logical paths that reflect a scheduling pattern.
Of the aforesaid options for identifying/specifying data files to load from a stage, which option in general is the fastest & best considerate?
- A. I
- B. IV
- C. II
- D. III
Answer: C
Explanation:
Explanation
Of the above options for identifying/specifying data files to load from a stage, providing a discrete list of files is generally the fastest; however, the FILES parameter supports a maximum of 1,000 files, meaning a COPY command executed with the FILES parameter can only load up to 1,000 files.
For example:
copy into load1 from @%load1/Snow1/ files=('mydata1.csv', 'mydata2.csv', 'mydata3.csv')
NEW QUESTION # 73
The following code is executed ina Snowflake environment with the default settings:
What will be the result of the select statement?
- A. 1John
- B. John
- C. 0
- D. SQL compilation error object CUSTOMER' does not exist or is not authorized.
Answer: C
NEW QUESTION # 74
What are characteristics of Snowpark Python packages? (Select THREE).
Third-party packages can be registered as a dependency to the Snowpark session using the session, import () method.
- A. The SQL command DESCRIBE FUNCTION will list the imported Python packages of the Python User-Defined Function (UDF).
- B. Third-party supported Python packages are locked down to prevent hitting
- C. Python packages can access any external endpoints
- D. Querying information__schema .packages will provide a list of supported Python packages and versions
- E. Python packages can only be loaded in a local environment
Answer: A,C,D
Explanation:
Explanation
The characteristics of Snowpark Python packages are:
Third-party packages can be registered as a dependency to the Snowpark session using the session.import() method.
The SQL command DESCRIBE FUNCTION will list the imported Python packages of the Python User-Defined Function (UDF).
Querying information_schema.packages will provide a list of supported Python packages and versions.
These characteristics indicate how Snowpark Python packages can be imported, inspected, and verified in Snowflake. The other options are not characteristics of Snowpark Python packages. Option B is incorrect because Python packages can be loaded in both local and remote environments using Snowpark. Option C is incorrect because third-party supported Python packages are not locked down to prevent hitting external endpoints, but rather restricted by network policies and security settings.
NEW QUESTION # 75
A secure function returns data coming through an inbound share
What will happen if a Data Engineer tries to assign usage privileges on this function to an outbound share?
- A. The Engineer will be able to share the secure function with other accounts
- B. An error will be returned because the Engineer cannot share data that has already been shared
- C. An error will be returned because only secure functions can be shared with inbound shares
- D. An error will be returned because only views and secure stored procedures can be shared
Answer: B
Explanation:
Explanation
An error will be returned because the Engineer cannot share data that has already been shared. A secure function is a Snowflake function that can access data from an inbound share, which is a share that is created by another account and consumed by the current account. A secure function can only be shared with an inbound share, not an outbound share, which is a share that is created by the current account and shared with other accounts. This is to prevent data leakage or unauthorized access to the data from the inbound share.
NEW QUESTION # 76
A company uses Amazon EMR as an extract, transform, and load (ETL) pipeline to transform data that comes from multiple sources. A data engineer must orchestrate the pipeline to maximize performance.
Which AWS service will meet this requirement MOST cost effectively?
- A. Amazon Managed Workflows for Apache Airflow (Amazon MWAA)
- B. AWS Glue Workflows
- C. Amazon EventBridge
- D. AWS Step Functions
Answer: D
Explanation:
Glue Workflows is for Glue job orchestration. C is for orchestration with different AWS services.
NEW QUESTION # 77
Which connector creates the RECORD_CONTENT and RECORD_METADATA columns in the existing Snowflake table while connecting to Snowflake?
- A. Python Connector
- B. Node.js connector
- C. Spark Connector
- D. Kafka Connector
Answer: D
Explanation:
Explanation
Apache Kafka software uses a publish and subscribe model to write and read streams of records, similar to a message queue or enterprise messaging system. Kafka allows processes to read and write messages asynchronously. A subscriber does not need to be connected directly to a publisher; a pub-lisher can queue a message in Kafka for the subscriber to receive later.
An application publishes messages to a topic, and an application subscribes to a topic to receive those messages. Kafka can process, as well as transmit, messages; however, that is outside the scope of this document. Topics can be divided into partitions to increase scalability.
Kafka Connect is a framework for connecting Kafka with external systems, including databases. A Kafka Connect cluster is a separate cluster from the Kafka cluster. The Kafka Connect cluster sup-ports running and scaling out connectors (components that support reading and/or writing between external systems).
The Kafka connector is designed to run in a Kafka Connect cluster to read data from Kafka topics and write the data into Snowflake tables.
Every Snowflake table loaded by the Kafka connector has a schema consisting of two VARIANT columns:
RECORD_CONTENT. This contains the Kafka message.
RECORD_METADATA. This contains metadata about the message, for example, the topic from which the message was read.
NEW QUESTION # 78
......
Snowflake DEA-C01 Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
| Topic 5 |
|
DEA-C01 Exam Dumps - PDF Questions and Testing Engine: https://prepaway.dumptorrent.com/DEA-C01-braindumps-torrent.html